
高级特性
概述
在前面一章中,我们介绍了在 AntDB 中使用 SQL 命令去存储和访问数据的基本方法。这章讨论了更多 SQL 命令的高级特性,可以用来简化对于数据的管理并且防止数据的丢失或损坏。
视图
先看看下面的这条 SELECT 命令:
SELECT ename, sal, sal * 24 AS yearly_salary, deptno FROM emp;
ENAME | SAL | YEARLY_SALARY | DEPTNO
--------+------+---------------+--------
SMITH | 800 | 19200 | 20
ALLEN | 1600 | 38400 | 30
WARD | 1250 | 30000 | 30
JONES | 2975 | 71400 | 20
MARTIN | 1250 | 30000 | 30
BLAKE | 2850 | 68400 | 30
CLARK | 2450 | 58800 | 10
SCOTT | 3000 | 72000 | 20
KING | 5000 | 120000 | 10
TURNER | 1500 | 36000 | 30
ADAMS | 1100 | 26400 | 20
JAMES | 950 | 22800 | 30
FORD | 3000 | 72000 | 20
MILLER | 1300 | 31200 | 10
(14 rows)
如果这个查询经常用到,那么可以使用这个查询来创建一个视图。这样就能以简便的方式重复使用这个查询,而无需每次重复输入整条SELECT命令(emp 表格定义见【示例参考表格】)。
CREATE VIEW employee_pay AS SELECT ename, sal, sal * 24 AS yearly_salary, deptno FROM emp;
在执行查询的过程中,我们可以像使用普通表名一样地使用视图名称employee_pay。
SELECT * FROM employee_pay;
ENAME | SAL | YEARLY_SALARY | DEPTNO
--------+------+---------------+---------
SMITH | 800 | 19200 | 20
ALLEN | 1600 | 38400 | 30
WARD | 1250 | 30000 | 30
JONES | 2975 | 71400 | 20
MARTIN | 1250 | 30000 | 30
BLAKE | 2850 | 68400 | 30
CLARK | 2450 | 58800 | 10
SCOTT | 3000 | 72000 | 20
KING | 5000 | 120000 | 10
TURNER | 1500 | 36000 | 30
ADAMS | 1100 | 26400 | 20
JAMES | 950 | 22800 | 30
FORD | 3000 | 72000 | 20
MILLER | 1300 | 31200 | 10
(14 rows)
充分使用视图是良好设计 SQL 数据库的关键部分。视图提供了一致性接口来封装数据表的详细结构,而表的结构在程序改动的时候是可以改变。
我们可以在使用真实表的地方使用视图。通常在其他视图的基础上创建视图这种使用方式不常见。
外键
假如想确保所有的雇员属于一个已存在的部门,那么这种约束就称为维护数据的参照完整性。在最简化的数据库系统中,是通过如下方式实现:首先在表 dept 中检查是否有匹配的记录存在,然后插入或拒绝新的雇员记录。这种方式有很多问题,并且非常的不方便。AntDB 为用户提供了一个更为简便的实现方式。
我们在章节 1.1.3 部分出现的表 emp 上加了一个外键,修改后的表 emp 是下面这个样子:
CREATE TABLE emp (
empno NUMBER(4) NOT NULL CONSTRAINT emp_pk PRIMARY KEY,
ename VARCHAR2(10),
job VARCHAR2(9),
mgr NUMBER(4),
hiredate DATE,
sal NUMBER(7,2),
comm NUMBER(7,2),
deptno NUMBER(2) CONSTRAINT emp_ref_dept_fk
REFERENCES dept(deptno)
);
如果在表 emp 中尝试运行下面的这条 INSERT 命令,那么外键约束 emp_ref_dept_fk 要确保部门编号为 50 的记录在表 dept 中存在。而事实上因为这个部门不存在,所以系统拒绝执行这个命令。
INSERT INTO emp VALUES (8000,'JONES','CLERK',7902,'17-AUG-07',1200,NULL,50);
ERROR: INSERT OR UPDATE ON TABLE "emp" violates foreign key constraint "emp_ref_dept_fk"
DETAIL: Key (deptno)=(50) is not present in table "dept".
通过利用外键的系统行为,可以对程序进行更良好的调整。正确使用外键会改进你所设计的数据库程序的质量,所以我们鼓励你学习更多关于外键的知识。
ROWID列
rowid 是一行的唯一标识,具有全局唯一性。
与 rowid 相关的参数设置有 2 个:
- default_with_rowids: 用于控制 rowid 开关。
-
default_with_rowid_id :用于生成 rowid 值的高位,默认值是无效值 -1。如果打开开关,需要将此值设置为 0-1023,但是不建议设置 0 和 1023,此值在产生第一个 rowid 值之后不可更改。
有三种方式打开 rowid 开关。
-
设置全局开关。
直接修改配置文档 postgresql.conf,设置如下参数:
default_with_rowids = on
此时,在数据库中创建的表都默认会有 rowid 列。
- session 级别设置。
在同一个 session 内,执行下面的语句,则只有在当前会话中创建的表默认带有 rowid 列。
SET default_with_rowids = on
- 表级别设置
create table 语句加 with rowid,如下所示:
CREATE TABLE tt(id int, sal int) WITH rowid;
INSERT INTO tt values(1, 1000),(2, 4000),(4, 8000);
SELECT rowid, * FROM tt;
ROWID | ID | SAL
--------------+----+------
ZAAAAAAAQAA= | 1 | 1000
ZQAAAAAAQAA= | 2 | 4000
ZgAAAAAAQAA= | 4 | 8000
(3 rows)
注意:更新一行数据时行,集群版本下,对应行 rowid 会更新。单机版本下,对应行 rowid 不会更新。因此,单机版本更加兼容 Oracle。
ROWNUM 伪列
ROWNUM 是一个伪列,它的作用就是根据从查询中获取记录的顺序,为每一条记录分配一个递增,唯一的整数值。因此 ROWNUM 的分配是按照第一条取出记录的 ROWNUM 是1,第二条取出记录的 ROWNUM 是 2,这样的顺序进行的。
我们可以使用这个特性去限制查询一次所获取的记录总数。在下面的示例中演示了这个特性:
SELECT empno, ename, job FROM emp WHERE ROWNUM < 5;
EMPNO | ENAME | JOB
-------+-------+----------
7369 | SMITH | CLERK
7499 | ALLEN | SALESMAN
7521 | WARD | SALESMAN
7566 | JONES | MANAGER
(4 rows)
ROWNUM 的值在结果集的排序操作发生之前把值分配给结果集中的每一条记录。因此,结果集是根据 ORDER BY 子句指定的顺序返回。但是正如在下面的示例中看到,在一个升序排序的输出中不是必须用到 ROWNUM 值。
SELECT ROWNUM, empno, ename, job FROM emp WHERE ROWNUM < 5 ORDER BY ename;
ROWNUM | EMPNO | ENAME | JOB
--------+---------+-------+----------
1 | 7876 | ADAMS | CLERK
2 | 7499 | ALLEN | SALESMAN
3 | 7698 | BLAKE | MANAGER
4 | 7782 | CLARK | MANAGER
(4 rows)
在下面的示例中显示了如何为表 jobhist 中每一条记录添加一个序列数。首先在表上增加一个名称为 seqno 的列,然后在 UPDATE 命令中把 ROWNUM 设定为 seqno。这样我们就为表 jobhist 增加一个带有序列数的列。
ALTER TABLE jobhist ADD column seqno NUMBER(3);
UPDATE jobhist SET seqno = ROWNUM;
下面的 SELECT 命令显示了新的 seqno 值(jobhist 表格定义见【示例参考表格】):
SELECT seqno, empno, TO_CHAR(startdate,'DD-MON-YY') AS start, job FROM jobhist;
SEQNO | EMPNO | START | JOB
-------+-------+-----------+-------------------
1 | 7369 | 17-DEC-80 | CLERK
2 | 7499 | 20-FEB-81 | SALESMAN
3 | 7521 | 22-FEB-81 | SALESMAN
4 | 7566 | 02-APR-81 | MANAGER
5 | 7654 | 28-SEP-81 | SALESMAN
6 | 7698 | 01-MAY-81 | MANAGER
7 | 7782 | 09-JUN-81 | MANAGER
8 | 7788 | 19-APR-87 | CLERK
9 | 7788 | 13-APR-88 | CLERK
10 | 7788 | 05-MAY-90 | ANALYST
11 | 7839 | 17-NOV-81 | PRESIDENT
12 | 7844 | 08-SEP-81 | SALESMAN
13 | 7876 | 23-MAY-87 | CLERK
14 | 7900 | 03-DEC-81 | CLERK
15 | 7900 | 15-JAN-83 | CLERK
16 | 7902 | 03-DEC-81 | ANALYST
17 | 7934 | 23-JAN-82 | CLERK
(17 rows)
层次查询
层次查询是一种特定类型的查询,用于在基于形成父子关系数据中以层次顺序返回结果集中的记录。层次通常是用一个反转顺序的树结构来表示的。树由相互连接的节点组成。每个节点都可能会连接 0 个、1 个、甚至多个子节点。除了最上层根节点没有父节点外,每个节点都会连接到一个父节点。每棵树都只有一个根节点。而没有任何子节点的节点称为叶节点。树至少有一个叶节点 - 例如,在最小的树就是由一个单独的节点组成,在这种情况下,这个节点既是根节点,也是叶节点。
在层次查询中,结果集中的记录表示一棵或多棵树中的节点。
注意:如果一条记录出现在多棵树中,这条记录就会在结果集中出现多次。
在查询中层次关系是通过 CONNECT BY 子句描述的,其中 CONNECT BY 子句决定了记录在结果集中返回的顺序。下面显示了 SELECT 命令中 CONNECT BY 子句的使用环境和相关的可选子句。
SELECT select_list FROM table_expression [ WHERE ...]
[ START WITH start_expression ]
CONNECT BY { PRIOR parent_expr = child_expr |
child_expr = PRIOR parent_expr }
[ ORDER SIBLINGS BY column1 [ ASC | DESC ]
[, column2 [ ASC | DESC ] ] ...
[ GROUP BY ...]
[ HAVING ...]
[ other ...]
select_list 是一个或多个表达式,包括结果集的字段。table_expression 是一张或多张表或者视图,是获取记录的来源。other 是任何附加的合法 SELECT 子句。在后面的章节中会介绍到与层次查询相关的子句例如 START WITH, CONNECT BY 和 ORDER SIBLINGS BY 等。
定义记录的父/子关系
对于任何指定的记录,它的父节点和子节点是由 CONNECT BY 子句来决定。CONNECT BY 子句必须由 2 个表达式组成,用等号进行比较。除此之外,这两个表达式必须以关键字 PRIOR 为前缀。
确定记录子节点的步骤如下:
-
在记录上计算 parent_expr。
-
从计算后 table_expression 中获取的其他记录,然后在这些记录上计算 child_expr。
-
如果 parent_expr 等于 child_expr,那么说明这条记录是记录的子节点。
-
在 table_expression 中的剩余记录中重复上面的计算过程。所有满足步骤 3 中等式关系的记录都是记录的子节点。
注意:决定一条记录是否是子节点的计算过程是在 WHERE 子句应用到 table_expression 前,在 table_expression 所返回的每一条记录上发生的。
通过迭代式反复执行这个过程一一将前面步骤中找到的子节点当成父节点,我们就构建了一棵由节点组成的颠倒树。当最终子节点集没有他们自己的子节点-也就是那些叶节点的时候,整个过程结束.包含 CONNECT BY 子句的 SELECT 命令通常包括 START WITH 子句。START WITH 子句用于决定作为根节点的记录。例如,初始化为父节点的记录取决于是前面介绍算法的应用。在下一节中将会详细解释这个子句。
选择根节点
START WITH 子句用于确定那些由 table_expression 查询出来做为根节点的的记录。所有由 table_expression 选择出来的记录变成树的根节点,其中 start_expression 计算为”true”。因此,在结果集中潜在树的数量等于根节点的数目。因此,如果没有使用 START WITH 子句,那么每一条由 table_expression 返回的记录都是它自己所拥有树的根节点。
在示例程序中树的组织形式
考虑一下在示例程序中的表 emp。根据包含主管经理雇员编号的 mgr 列,表 emp 中的记录形成一个层次结构。每个雇员最多只有一个经理。KING 是公司的董事长,他没有主管经理。由此,记录为 KING 的 mgr 列是空的。同时,也存在这样一种可能,一个雇员可以是多个雇员的经理。如下所示,这种关系形成了典型的树状结构图。
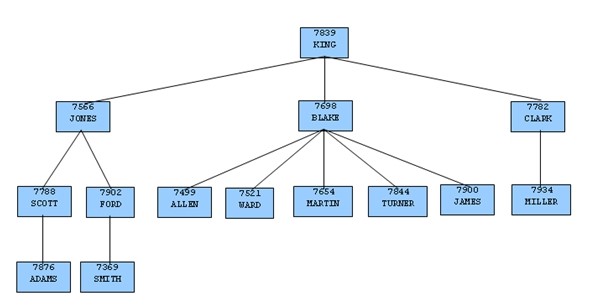
为形成一个基于这种关系的层次查询,SELECT 命令须包括子句 CONNECT BY PRIOR empno = mgr。例如,对于公司的董事长,雇员号为 7839 的 KING,任何 mgr 列是 7839 的雇员都是直接向 KING 汇报。(包括 JONES,BLAKE 和 CLARK,这些都是 KING 的子节点)。类似的情况下,对于雇员 JONES 来说,任何其他雇员的 mgr 列为 7566 的都是 JONES 记录的子节点-在这个示例中包括 SCOTT 和 FORD。
组织结构图的最上层是 KING,所以在这棵树里只有一个根节点。START WITH mgr IS NULL 子句只选择 KING 作为初始化根节点。
完整的 SELECT 命令显示如下(emp 表格定义见【示例参考表格】)。
SELECT ename, empno, mgr
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr;
查询输出中记录以从上到下,从左到右的顺序从根节点到叶节点遍历了每一个分枝。下面是这个查询的输出。
ENAME | EMPNO | MGR
--------+-------+------
KING | 7839 |
CLARK | 7782 | 7839
BLAKE | 7698 | 7839
JONES | 7566 | 7839
MILLER | 7934 | 7782
JAMES | 7900 | 7698
TURNER | 7844 | 7698
MARTIN | 7654 | 7698
WARD | 7521 | 7698
ALLEN | 7499 | 7698
FORD | 7902 | 7566
SCOTT | 7788 | 7566
SMITH | 7369 | 7902
ADAMS | 7876 | 7788
(14 rows)
节点的层次
LEVEL 是一个伪列,可以在 SELECT 命令中出现列的地方使用。对于结果集中的每一条记录,LEVEL 都会返回一个非零的整数值来指定由这条记录所表示的节点层次深度。分配的顺序是按照根节点 LEVEL 是 1,根节点的直接子节点 LEVEL 是 2 进行的。
在下面的查询中对上一条查询命令进行了修改,在语句中加上了 LEVEL 伪列。除此之外,通过使用 LEVEL 值,雇员名称被缩进,这样能够进一步强调每条记录在层次中的深度(emp 表格定义见【示例参考表格】)。
SELECT LEVEL, LPAD (' ', 2 * (LEVEL - 1)) || ename "employee", empno, mgr
FROM emp START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr;
这个查询的输出如下:
LEVEL | employee | EMPNO | MGR
-------+-------------+-------+------
1 | KING | 7839 |
2 | CLARK | 7782 | 7839
2 | BLAKE | 7698 | 7839
2 | JONES | 7566 | 7839
3 | MILLER | 7934 | 7782
3 | JAMES | 7900 | 7698
3 | TURNER | 7844 | 7698
3 | MARTIN | 7654 | 7698
3 | WARD | 7521 | 7698
3 | ALLEN | 7499 | 7698
3 | FORD | 7902 | 7566
3 | SCOTT | 7788 | 7566
4 | SMITH | 7369 | 7902
4 | ADAMS | 7876 | 7788
(14 rows)
排序同层次节点
同层次节点共享一个父节点,并且是在相同层次上的节点。例如,在上面的输出中,雇员 ALLEN、WARD、MARTIN、TURNER 和 JAMES 就是同层次节点,这是因为他们在相同层次上,有一个共同的一个父节点 BLAKE。JONES,BLAKE 和 CLARK 也是同层次节点,因为他们在相同的层次上,并且拥有共同的父节点 KING。
通过使用 ORDER SIBLINGS BY 子句来查询列的值,同层次节点可以以升序或者降序的顺序出现。这样就实现了对结果集的排序。这是ORDER BY 句特定的使用情况,只能用于层次查询。
通过增加 ORDER SIBLINGS BY ename ASC 子句,我们对上一个查询做出进一步修改(emp 表格定义见【示例参考表格】)。
SELECT LEVEL, LPAD (' ', 2 * (LEVEL - 1)) || ename "employee", empno, mgr
FROM emp START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr
ORDER SIBLINGS BY ename ASC;
现在查询的输出结果已经修改了,所以同层次节点根据名称以升序的顺序出现。在 KING 下面的同层次节点 BLAKE、CLARK 和 JONES 是以字母顺序出现的。在 BLAKE 下面的同层次节点 ALLEN、JAMES、MARTIN、TURNER 和 WARD 也是以字母顺序出现的。
LEVEL | employee | EMPNO | MGR
-------+-------------+-------+------
1 | KING | 7839 |
2 | BLAKE | 7698 | 7839
3 | ALLEN | 7499 | 7698
3 | JAMES | 7900 | 7698
3 | MARTIN | 7654 | 7698
3 | TURNER | 7844 | 7698
3 | WARD | 7521 | 7698
2 | CLARK | 7782 | 7839
3 | MILLER | 7934 | 7782
2 | JONES | 7566 | 7839
3 | FORD | 7902 | 7566
4 | SMITH | 7369 | 7902
3 | SCOTT | 7788 | 7566
4 | ADAMS | 7876 | 7788
(14 rows)
在最后的这个示例中增加了 WHERE 子句,并且查询从 3 个根节点开始。在构建完节点树后,WHERE 子句过滤出树中的记录,这样就形成了最终结果集(emp 表格定义见【示例参考表格】)。
SELECT LEVEL, LPAD (' ', 2 * (LEVEL - 1)) || ename "employee", empno, mgr
FROM emp WHERE mgr IN (7839, 7782, 7902, 7788)
START WITH ename IN ('BLAKE','CLARK','JONES')
CONNECT BY PRIOR empno = mgr
ORDER SIBLINGS BY ename ASC;
查询的输出结果集显示根节点(LEVEL1)- BLAKE,CLARK 和 JONES。
除此之外,不满足 WHERE 子句的记录不会在输出中出现。
LEVEL | employee | EMPNO | MGR
-------+-----------+-------+------
1 | BLAKE | 7698 | 7839
1 | CLARK | 7782 | 7839
2 | MILLER | 7934 | 7782
1 | JONES | 7566 | 7839
3 | SMITH | 7369 | 7902
3 | ADAMS | 7876 | 7788
(6 rows)
多维分析
多维分析是指在数据仓库应用程序中常用的使用各种维度组合检查数据的过程。维度是用于对数据进行分类的类别,如时间、地理位置、公司部门、产品线等等。与特定维度集相关联的结果称为事实。事实通常是与产品销售、利润、数量、数量等相关的数字。
为了根据关系数据库系统中的一组维度获取这些事实,通常使用 SQL 聚合。SQL 聚合基本上意味着根据某些标准(维度)对数据进行分组,结果集由每个组中数据的计数、总和和平均值等事实的聚合组成。
SQL SELECT 命令的 GROUP BY 子句支持以下命令,这些命令简化了生成聚合结果的过程。
-
ROLLUP
-
CUBE
-
GROUPING SETS
ROLLUP扩展
ROLLUP 是 GROUP BY 语句的扩展。作用是按照 ROLLUP 子句中指定的分组列表,创建从最详细级别汇总到总计的小计。首先他会计算出指定在 GROUP BY 子句中标准合计值,然后他会渐进地创建更高级别的合计值,是通过在 GROUP BY 子句列表中多列的右边第一个列开始往左边移动。最终,它会计算总和。
ROLLUP 的语法如下:
GROUP BY ROLLUP ( attributeList )
分组级别或总计的数量为 n +1,其中 n 表示 ROLLUP 表达式列表中的项目数。带括号的列表算作一项。
如果是 Group by ROLLUP(A, B, C) 的话,首先会对 (A、B、C) 进行 GROUP BY,然后对 (A、B) 进行 GROUP BY,然后是 (A) 进行 GROUP BY,最后对全表进行 GROUP BY 操作。
如果是 GROUP BY A, ROLLUP(B, C),GROUP BY 子句在 (2+1=3) 聚合级别创建小计。也就是说,在级别(A, B, C), (B,C) 和 (A)。
在 GROUP BY 子句的上下文中指定的 ROLLUP 如下所示:
SELECT select_list FROM ...
GROUP BY [... ,] ROLLUP ( expression_list ) [, ...]
select_list 中指定的项目也必须出现在 ROLLUP expression_list 中;或者它们必须是诸如 COUNT,SUM,AVG,MIN 或 MAX 之类的集合函数;或者它们必须是常量或函数,其返回值与组中的各个行无关(例如,SYSDATE 函数)。
如果希望输出以层次结构或其他有意义的结构显示,则应使用 ORDER BY 子句。如果未指定 ORDER BY 子句,则不能保证结果集的顺序(emp 和 dept 表格定义见【示例参考表格】)。
示例:
SELECT loc, dname, job, COUNT(*) AS "employees" FROM emp e, dept d
WHERE e.deptno = d.deptno
GROUP BY ROLLUP (loc, dname, job)
ORDER BY 1, 2, 3;
以下是查询的结果。loc,dname 和 job 的每个唯一组合的员工数,以及 loc 和 dname 的每个唯一组合的小计,loc 的每个唯一值的总和,最后一行显示总计。
LOC | DNAME | JOB | employees
----------+------------+-------------+------------
CHICAGO | SALES | CLERK | 1
CHICAGO | SALES | MANAGER | 1
CHICAGO | SALES | SALESMAN | 4
CHICAGO | SALES | | 6
CHICAGO | | | 6
DALLAS | RESEARCH | ANALYST | 2
DALLAS | RESEARCH | CLERK | 2
DALLAS | RESEARCH | MANAGER | 1
DALLAS | RESEARCH | | 5
DALLAS | | | 5
NEW YORK | ACCOUNTING | CLERK | 1
NEW YORK | ACCOUNTING | MANAGER | 1
NEW YORK | ACCOUNTING | PRESIDENT | 1
NEW YORK | ACCOUNTING | | 3
NEW YORK | | | 3
| | | 14
(16 rows)
如果 ROLLUP 列表中的前两列用圆括号括起来,那么小计级别也不同(emp 和 dept 表格定义见【示例参考表格】)。
SELECT loc, dname, job, COUNT(*) AS "employees" FROM emp e, dept d
WHERE e.deptno = d.deptno
GROUP BY ROLLUP ((loc, dname), job)
ORDER BY 1, 2, 3;
现在对于每个唯一的 loc 和 dname 组合都有一个小计,但是对于 loc 的唯一值没有小计。
LOC | DNAME | JOB | employees
----------+------------+-----------+-----------
CHICAGO | SALES | CLERK | 1
CHICAGO | SALES | MANAGER | 1
CHICAGO | SALES | SALESMAN | 4
CHICAGO | SALES | | 6
DALLAS | RESEARCH | ANALYST | 2
DALLAS | RESEARCH | CLERK | 2
DALLAS | RESEARCH | MANAGER | 1
DALLAS | RESEARCH | | 5
NEW YORK | ACCOUNTING | CLERK | 1
NEW YORK | ACCOUNTING | MANAGER | 1
NEW YORK | ACCOUNTING | PRESIDENT | 1
NEW YORK | ACCOUNTING | | 3
| | | 14
CUBE 扩展
CUBE 扩展类似于 ROLLUP 扩展。但是,与 ROLLUP 不同,ROLLUP 产生分组并基于 ROLLUP 表达式列表中项目的从左到右列表产生层次结构,而 CUBE 基于 CUBE 表达式列表中所有项目的每个排列产生分组和小计。因此,与在同一表达式列表上执行的 ROLLUP 相比,结果集包含的行更多。
CUBE(A, B, C),则首先会对 (A、B、C) 进行 GROUPBY,然后依次是 (A、B),(A、C),(A),(B、C),(B),(C),最后对全表进行 GROUPBY操作。有 2 的 N 次方种组合方式。
示例:
以下查询根据 loc,dname 和 job列的排列产生一个多维数据集(emp 和 dept 表格定义见【示例参考表格】)。
SELECT loc, dname, job, COUNT(*) AS "employees" FROM emp e, dept d
WHERE e.deptno = d.deptno
GROUP BY CUBE (loc, dname, job)
ORDER BY 1, 2, 3;
以下是查询的结果。对于 loc,dname 和 job 的每种组合,都有一个雇员数量的计数,对于 loc 和 dname 的每种组合,对于 loc 和 job 的每种组合,对于 dname 和 job 的每种组合,每种都有小计。loc 的唯一值,dname 的每个唯一值,job 的每个唯一值以及最后一行上显示的总计。
LOC | DNAME | JOB | employees
----------+------------+-----------+-------------
CHICAGO | SALES | CLERK | 1
CHICAGO | SALES | MANAGER | 1
CHICAGO | SALES | SALESMAN | 4
CHICAGO | SALES | | 6
CHICAGO | | CLERK | 1
CHICAGO | | MANAGER | 1
CHICAGO | | SALESMAN | 4
CHICAGO | | | 6
DALLAS | RESEARCH | ANALYST | 2
DALLAS | RESEARCH | CLERK | 2
DALLAS | RESEARCH | MANAGER | 1
DALLAS | RESEARCH | | 5
DALLAS | | ANALYST | 2
DALLAS | | CLERK | 2
DALLAS | | MANAGER | 1
DALLAS | | | 5
NEW YORK | ACCOUNTING | CLERK | 1
NEW YORK | ACCOUNTING | MANAGER | 1
NEW YORK | ACCOUNTING | PRESIDENT | 1
NEW YORK | ACCOUNTING | | 3
NEW YORK | | CLERK | 1
NEW YORK | | MANAGER | 1
NEW YORK | | PRESIDENT | 1
NEW YORK | | | 3
| ACCOUNTING | CLERK | 1
| ACCOUNTING | MANAGER | 1
| ACCOUNTING | PRESIDENT | 1
| ACCOUNTING | | 3
| RESEARCH | ANALYST | 2
| RESEARCH | CLERK | 2
| RESEARCH | MANAGER | 1
| RESEARCH | | 5
| SALES | CLERK | 1
| SALES | MANAGER | 1
| SALES | SALESMAN | 4
| SALES | | 6
| | ANALYST | 2
| | CLERK | 4
| | MANAGER | 3
| | PRESIDENT | 1
| | SALESMAN | 4
| | | 14
(42 rows)
GROUPING SETS 扩展
在 GROUP BY 子句中使用 GROUPING SETS 扩展提供了一种生成一个结果集的方法,该结果集实际上是基于不同分组的多个结果集的串联。换句话说,执行 UNION ALL 操作将多个分组的结果集组合为一个结果集。
请注意是 UNION ALL 操作,因此 GROUPING SETS 扩展不会从组合在一起的结果集中消除重复的行。
grouping sets 就是对参数中的每个参数做 grouping,也就是有几个参数做几次 grouping,例如使用 group by grouping sets(A,B,C),则对 (A),(B),(C) 进行 group by,如果使用 group by grouping sets((A,B),C),则对 (A,B),(C) 进行 group by。
单个 GROUPING SETS 扩展的语法如下:
GROUPING SETS (
{ expr_1 | ( expr_1a [, expr_1b ] ...) |
ROLLUP ( expr_list ) | CUBE ( expr_list )
} [, ...] )
GROUPING SETS 扩展可以包含一个或多个逗号分隔的表达式,括在括号内的表达式列表,ROLLUP 扩展和 CUBE 扩展的任意组合。
GROUPING SETS 扩展是在 GROUP BY 子句的上下文中指定的,如下所示:
SELECT select_list FROM ...
GROUP BY [... ,] GROUPING SETS ( expression_list ) [, ...]
select_list 中指定的项目也必须出现在 GROUPING SETS expression_list 中。或者它们必须是诸如 COUNT,SUM,AVG,MIN 或 MAX 之类的集合函数;或者它们必须是常量或函数,其返回值与组中的各个行无关(例如,SYSDATE 函数)。
如果希望输出以有意义的结构显示,则应使用 ORDER BY 子句。 如果未指定 ORDER BY 子句,则不能保证结果集的顺序。
以下查询生成由列 loc,dname 和 job 给出的组的并集(emp 和 dept 表格定义见【示例参考表格】)。
SELECT loc, dname, job, COUNT(*) AS "employees" FROM emp e, dept d
WHERE e.deptno = d.deptno
GROUP BY GROUPING SETS (loc, dname, job)
ORDER BY 1, 2, 3;
结果如下:
LOC | DNAME | JOB | employees
----------+------------+-----------+-----------
CHICAGO | | | 6
DALLAS | | | 5
NEW YORK | | | 3
| ACCOUNTING | | 3
| RESEARCH | | 5
| SALES | | 6
| | ANALYST | 2
| | CLERK | 4
| | MANAGER | 3
| | PRESIDENT | 1
| | SALESMAN | 4
(11 rows)
这等效于以下查询,该查询使用 UNION ALL 运算符(emp 和 dept 表格定义见【示例参考表格】)。
SELECT NULL, dname, NULL, COUNT(*) AS "employees" FROM emp e, dept d
WHERE e.deptno = d.deptno
GROUP BY dname
UNION ALL
SELECT NULL, NULL, job, COUNT(*) AS "employees" FROM emp e, dept d
WHERE e.deptno = d.deptno
GROUP BY job
ORDER BY 1, 2, 3;
以下示例显示了如何在 GROUPING SETS 表达式列表中一起使用各种类型的 GROUP BY 扩展名(emp 和 dept 表格定义见【示例参考表格】)。
SELECT loc, dname, job, COUNT(*) AS "employees" FROM emp e, dept d
WHERE e.deptno = d.deptno
GROUP BY GROUPING SETS (loc, ROLLUP (dname, job), CUBE (job, loc))
ORDER BY 1, 2, 3;
输出是结果集的串联,这些结果集将分别从 GROUP BY loc,GROUP BY ROLLUP(dname,job)和 GROUP BY CUBE(job,loc)产生。
LOC | DNAME | JOB | employees
----------+------------+-------------+------------
CHICAGO | | CLERK | 1
CHICAGO | | MANAGER | 1
CHICAGO | | SALESMAN | 4
CHICAGO | | | 6
CHICAGO | | | 6
DALLAS | | ANALYST | 2
DALLAS | | CLERK | 2
DALLAS | | MANAGER | 1
DALLAS | | | 5
DALLAS | | | 5
NEW YORK | | CLERK | 1
NEW YORK | | MANAGER | 1
NEW YORK | | PRESIDENT | 1
NEW YORK | | | 3
NEW YORK | | | 3
| ACCOUNTING | CLERK | 1
| ACCOUNTING | MANAGER | 1
| ACCOUNTING | PRESIDENT | 1
| ACCOUNTING | | 3
| RESEARCH | ANALYST | 2
| RESEARCH | CLERK | 2
| RESEARCH | MANAGER | 1
| RESEARCH | | 5
| SALES | CLERK | 1
| SALES | MANAGER | 1
| SALES | SALESMAN | 4
| SALES | | 6
| | ANALYST | 2
| | CLERK | 4
| | MANAGER | 3
| | PRESIDENT | 1
| | SALESMAN | 4
| | | 14
| | | 14
(34 rows)
GROUPING 函数
GROUPING 函数是 GROUPING SETS,CUBE 和 ROLLUP 的帮助函数。在对 GROUP BY 子句使用 ROLLUP,CUBE 或 GROUPING SETS 扩展时,有时可能难以区分扩展生成的各个小计级别以及结果集中的基础聚合行。GROUPING 函数提供了一种区分方法。
下面显示了使用 GROUPING 函数的一般语法。
SELECT [ expr ...,] GROUPING( col_expr ) [, expr ] ...
FROM ...
GROUP BY [...,]
{ ROLLUP | CUBE | GROUPING SETS }( [...,] col_expr
[, ...] ) [, ...]
GROUPING 函数参数只有一个,该参数必须是 GROUP BY 子句的 ROLLUP,CUBE 或 GROUPING SETS 扩展的表达式列表中指定的维列的表达式。表示结果集的一行是否对该列做了 grouping。对于对该列做了 grouping 的行而言,grouping()=0,反之为 1;以下查询显示GROUPING 函数的返回值如何对应于小计行(emp 和 dept 表格定义见【示例参考表格】)。
SELECT loc, dname, job, COUNT(*) AS "employees",
GROUPING(loc) AS "gf_loc",
GROUPING(dname) AS "gf_dname",
GROUPING(job) AS "gf_job"
FROM emp e, dept d
WHERE e.deptno = d.deptno
GROUP BY ROLLUP (loc, dname, job)
ORDER BY 1, 2, 3;
在最右三列中显示 GROUPING 函数输出的列中,小计行上对应于各列的值的小计将显示为 1。
LOC | DNAME | JOB | employees | gf_loc | gf_dname | gf_job
----------+------------+-----------+-----------+--------+----------+--------
CHICAGO | SALES | CLERK | 1 | 0 | 0 | 0
CHICAGO | SALES | MANAGER | 1 | 0 | 0 | 0
CHICAGO | SALES | SALESMAN | 4 | 0 | 0 | 0
CHICAGO | SALES | | 6 | 0 | 0 | 1
CHICAGO | | | 6 | 0 | 1 | 1
DALLAS | RESEARCH | ANALYST | 2 | 0 | 0 | 0
DALLAS | RESEARCH | CLERK | 2 | 0 | 0 | 0
DALLAS | RESEARCH | MANAGER | 1 | 0 | 0 | 0
DALLAS | RESEARCH | | 5 | 0 | 0 | 1
DALLAS | | | 5 | 0 | 1 | 1
NEW YORK | ACCOUNTING | CLERK | 1 | 0 | 0 | 0
NEW YORK | ACCOUNTING | MANAGER | 1 | 0 | 0 | 0
NEW YORK | ACCOUNTING | PRESIDENT | 1 | 0 | 0 | 0
NEW YORK | ACCOUNTING | | 3 | 0 | 0 | 1
NEW YORK | | | 3 | 0 | 1 | 1
| | | 14 | 1 | 1 | 1
(16 rows)